



A Brave New World
Cloud-based computing has changed the face of IT for the better. It has enabled organizations to make use of high-performance resources without requiring large IT groups. And it has enabled a supply of production-ready applications to companies who might not otherwise be able to access them. This is especially true in the world of Deep Learning, where high performance, scalability, and flexibility are critical.
But what if your organization can’t make use of the public cloud?
- You might have regulatory, competitive, or security concerns
- Your data sets might be too large for practical transfer or storage
- Depending upon your size and resource requirements, you might find the public cloud too expensive
All of those benefits would slip through your grasp. At least they would, unless there was a way to offer them with on-premises equipment.
The challenges of developing and deploying your Deep Learning applications on-premises are well known to organizations that have attempted it. Simply getting the platform into an operational state is daunting enough, given the number and complexity of the software components that need to interoperate.

And once you have pieced together that puzzle, the challenges of maintenance and system management raise their head. Furthermore, the platform must provide the performance benefits that are the primary goal of the exercise. Otherwise, what is the point?
Finally, once the software actually performs as expected in the happy path, there is a major uphill battle in making the solution predictable and robust, handling the corner cases, and anticipating the unexpected user behaviors that could break the system. All this is critical to an enterprise-grade solution.
Who wants to do all that? The primary goal of a data scientist is to address messy and difficult real world problems, not to become an IT expert.
NVIDIA®, Lenovo™, Mellanox®, and One Convergence have partnered to bring cloud-native capability to the on-premises Deep Learning community. The companies provide fast, robust scale-out systems that offer the best of both worlds: simplicity and performance. And at an outstanding set of cost points.
Let’s explore in more detail the goals of this partnership, the challenges that need to be overcome, and the resulting solution.
What Organizations Want
If you ask a dozen different organizations who specialize in Deep Learning what their ideal environment would look like, you will get a surprisingly similar answer. They all suffer from the same obstacles getting their systems to production.
Scaling: It’s Not All the Same
There are different ways to add resources to your system, each with advantages and challenges. The simplest approach, referred to as vertical scale-up, consists of a single highly specialized node, where additional resources are added to the box as needed. This works for many high-performance, compute-intensive applications, but does not always have the highest utilization for Deep Learning.
- Scale-up is limited to the physical capacity of the specialized platform
- The types of resources that you can add is likely to be limited for a single box, based on the design target
- Boxes that accommodate larger amounts of resources, and more flexibility, tend to be expensive

From a performance perspective, scale-up is the gold standard with the highest throughput, and it offers the most straightforward management footprint.
However, since any resource limit in Deep Learning is bad news, a fully scale-up implementation is seldom enough. A better approach is to expand the resources in a horizontal scale-out manner. Scale-out is implemented by adding nodes to a cluster, and treating them as a single entity from a resource and management perspective. This has a number of advantages:
- The number of resources possible in the cluster is large
- Clustering nodes together is going to be the most cost-effective approach to scaling
- Scale-out offers the maximum flexibility, since you can add nodes that have the best mix of CPUs, GPUs, and storage
- Adding nodes horizontally over time allows the newest technology to be accommodated in the system
- A horizontal approach allows you to start small - with perhaps a single CPU and several GPUs - and expand as necessary over time
Of course, the best approach is to allow both scale-up and scale-out, since each has its place. A hybrid approach must make the entire cluster management seamless, regardless of where the resources reside.
That’s Easy for You to Say
Given the clear advantages of horizontal scale-out, you might ask why everyone doesn’t do it that way. Because it’s hard. It’s relatively straightforward to hook up the hardware, but beyond that nothing comes easy, especially in a production environment, when - literally - time is money.
- There are open source frameworks, such as Kubeflow, that assist with a Deep Learning workflow, but they don’t simply work without some amount of effort.
- In a simple vertical scale-up system, after you’ve pieced together the components and made them reliable, you are well set to start performing data science activities. But for an on-premises system that is distributed horizontally, you have just started. It is a major challenge to set up your distributed system for simple operation and reasonable performance.
- One of the biggest hurdles is enabling the full power of the underlying platform within the application. You want to keep those expensive resources busy, which entails having access to the resources from anywhere on the cluster, and actively managing them at the application level.
Pulling it All Together
In order to address the requirements outlined, and to overcome the challenges inherent in on-premises computing, Mellanox®, Lenovo™, One Convergence, and NVIDIA® are offering a coordinated, production-ready Deep Learning environment.
The fundamental underpinning of the solution is a set of platforms - hardware and software - that are guaranteed to operate in a production setting. These platforms offer state-of-the-art components that are assembled and pre-tested to meet customer goals.
Lenovo™ Servers
Lenovo™ is a leader in high performance, affordable data center platforms. The Deep Learning system described in this paper features a ThinkSystem™ SD530 rack server, which forms a solid, scalable foundation for the solution.

- Designed for critical high performance enterprise workload environments
- Features an ultra-dense 2U, 4-node Lenovo™ D2 enclosure that delivers leadership performance in a compact form factor
- Accommodates the newest generation of GPUs to create a platform well suited to demanding Deep Learning applications
- Ultra-agile shuttle design features a highly flexible modular capability
- Ideal for scale-out implementations by combining the server with RDMA-enabled Ethernet NICs, enabling linear scaling as nodes are added to the system
- Allows your data science community to build the system that best meets your needs – both at the start of your project and as your organization grows
- Embedded management using Lenovo™’s powerful xClarity® Controller and xClarity® Administrator application
NVIDIA® GPUs
NVIDIA® technology has been a driving force in expanding the capabilities of Deep Learning. The Tesla V100 is at the heart of this revolution in artificial intelligence.

- Engineered for the convergence of AI and HPC
- Designed to achieve extreme performance levels: Tensor performance of 125 teraFlops and memory bandwidth of 900 GB/s
- Architecture is optimized for Deep Learning applications
- Enables linear performance improvement on scale-out systems with RDMA-enabled Ethernet connectivity
- Adopted by enterprise data centers and leading cloud vendors, enabling straightforward migration between on-premises environments and cloud platforms
- Supported by a family of optimized libraries
- Compatible with the industry’s top frameworks and applications
Mellanox® NICs
Mellanox® has been a leader in high performance connectivity since the company’s founding. The Intelligent ConnectX®-5 adapter cards offer the performance and features needed for on-premises Deep Learning.

- Delivers high bandwidth, low latency, and high computation efficiency
- Well suited for high-performance, data-intensive, and scalable compute and storage platforms
- Utilizes RoCE (RDMA over Converged Ethernet) technology, delivering low latency and high performance
- Enables linear scale-out performance improvement through optimized RDMA capability
- Features innovative transport service Dynamic Connected Transport (DCT) to ensure extreme scalability
- Supports Burst Buffer offload for background check pointing without interfering with the main CPU operations
- Supports quick and easy addition of nodes through convenient, reliable Ethernet connectivity
One Convergence DKube Application
The One Convergence DKube application builds on - and brings together - the hardware subsystems and drivers that form the infrastructure.

- Supports the Kubeflow open source reference platform, enhanced with additional features to better support ease of use - and made production-ready for enterprise customers
- Cloud-native solution based on Kubernetes, allowing simple migration
- Offers fast, easy installation - bare metal to data science within 4 hours
- Consists of an intuitive UI that supports the full data science workflow
- Manages distributed, heterogeneous resources available from within the application
- Includes an Operator dashboard to view and manage the infrastructure from within the application
- Supports multi-tenancy, allowing different organizations to get access to the resources, enables maximum resource utilization, and provides security between organizations
Real World Performance

In order to demonstrate the results of the work that has been described, it is important that the solution - especially leadership performance - can be attained on an actual system built as per these discussions.
Image classification is a typical use case for Deep Learning. Applications for image classification include security, healthcare, self-driving cars, and text recognition. It is very difficult for traditional software algorithms to handle, since each image of the entity is likely to be different; shifted, distorted, misaligned, etc. Deep neural networks are well suited to handling the types of distortions that brittle algorithms struggle with.
However, the nature of these massive neural networks strains traditional compute processors and requires an accelerated computing platform capable of achieving hundreds of teraFLOPS of computation. NVIDIA® V100 GPUs enable rapid training of deep learning models, solving in hours - or minutes - what traditional processors have in the past taken days or weeks to solve.
In order to help data scientists compare different platforms for image classification, a set of benchmarks has been developed that take standard models and measure the training performance.
The benchmark that was used for the measurements in this paper is tf-cnn, a common TensorFlow benchmark. The model is ResNet-50 and the training uses synthetic data.
The system used for the test has the following specifications

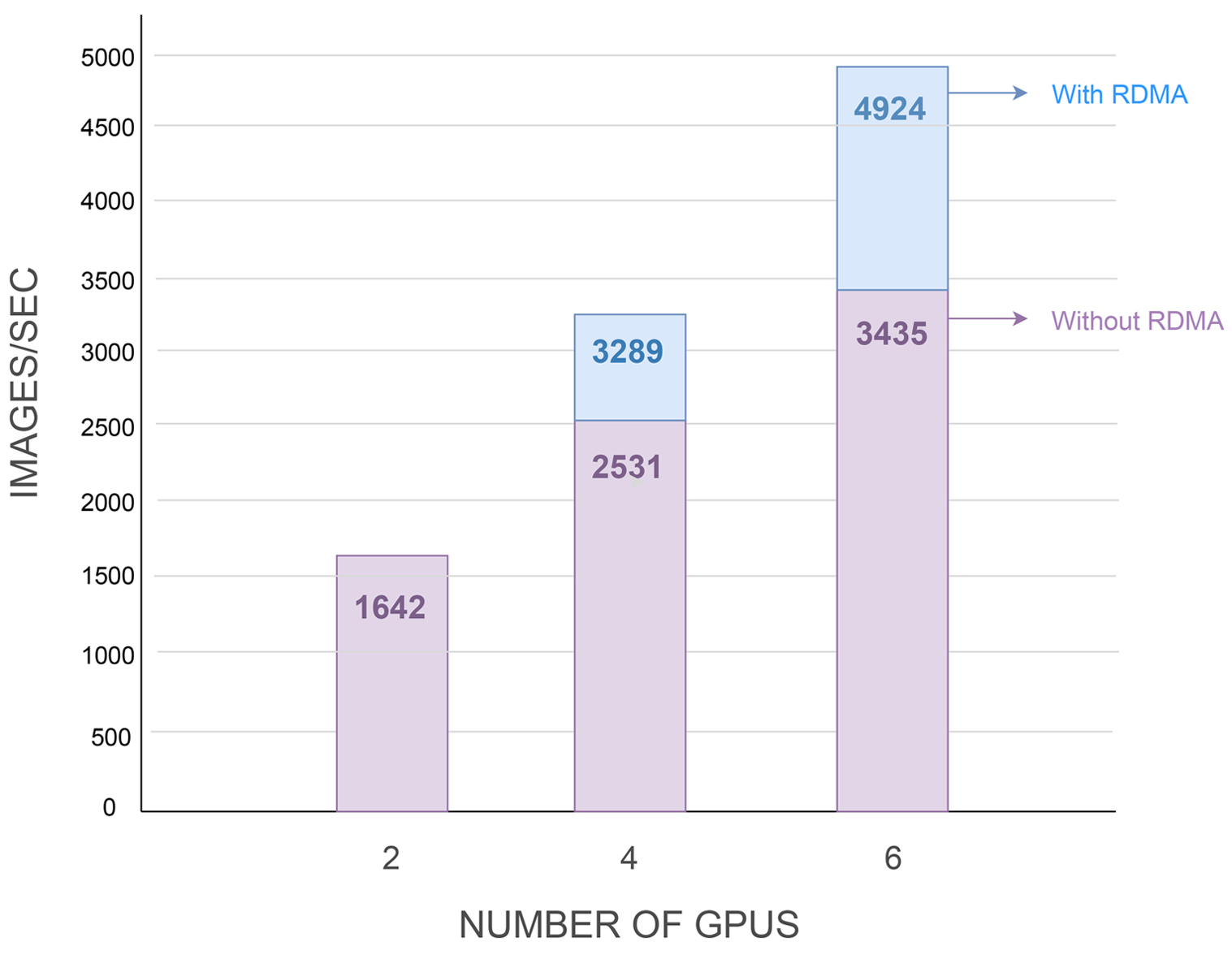
The benchmark results demonstrate that the performance scales as more GPUs are added through additional nodes, and that it scales linearly when RDMA is enabled.
Summary
This article has outlined the primary reasons for using a scale-out or hybrid approach, rather than simple scale-up, where performance requirements go beyond what can be achieved in a single box. Although a scale-out system is more difficult to deploy and manage, the complexity can be hidden by close cooperation among the vendors, and by a software solution that makes the best use of that cooperation.
Lenovo™, NVIDIA®, Mellanox®, and One Convergence have formed a partnership that addresses the issues inherent in scale-out deployment, and offer a simple, flexible, high-performance set of products that are tested to work together in an enterprise environment.
The companies have demonstrated that the resulting system offers linear performance scaling.
You can find out more about these solutions by visiting www.dkube.io





