

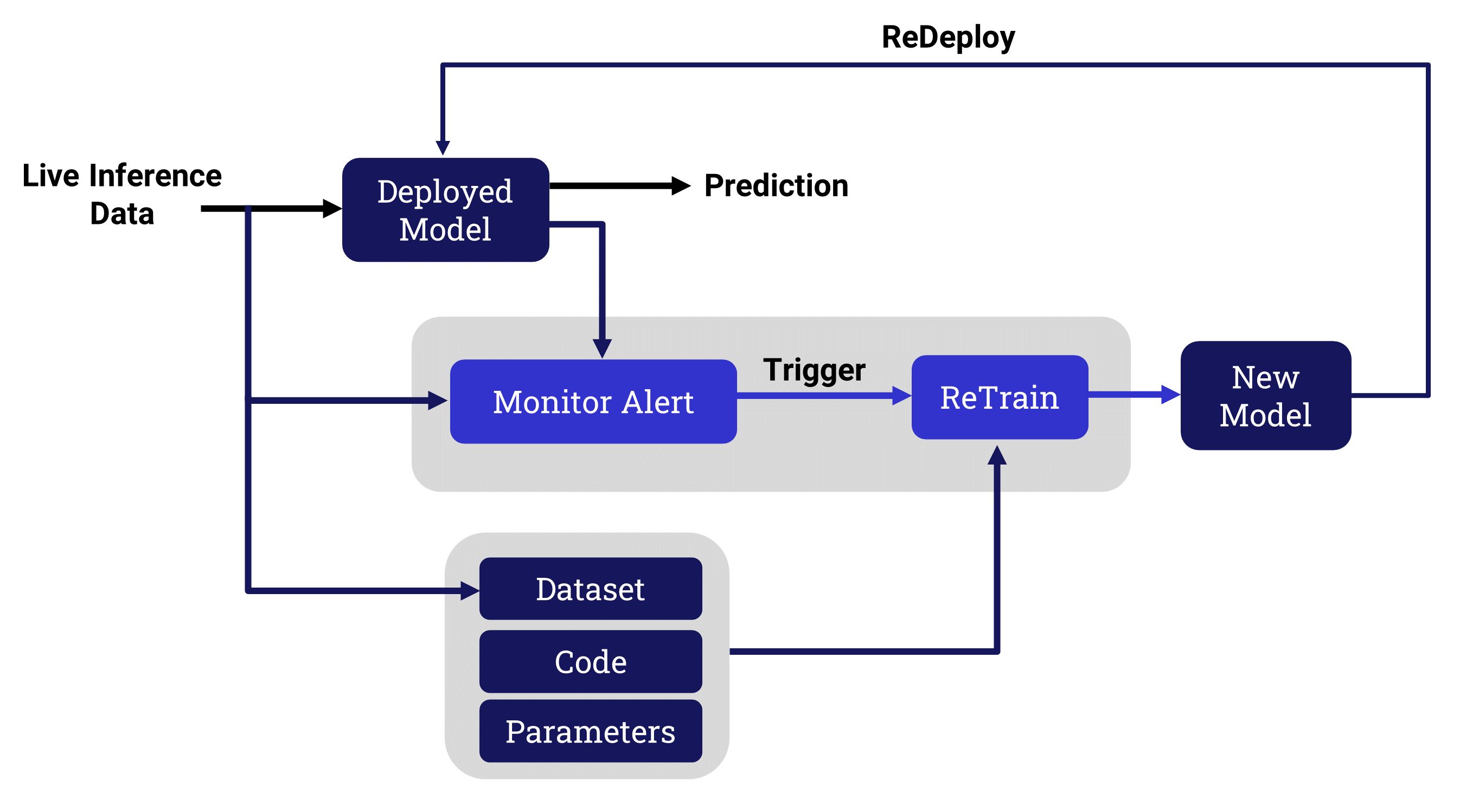

Machine learning has been traditionally focused on the important initial training phase. This ensures that a model will provide the best outcomes for the expected live data stream - at least for a while. However, it is well known within the machine learning community that however good a job you do at training a model, your results will degrade over time.
To address this reality, models need to be monitored and improved on a regular basis. The AI/ML team are required to take the following steps to identify and achieve this:

This is especially challenging for on-prem development, where the data needs to be near the machine learning system for reasons of compliance or security. This is common in the life sciences, insurance and federal/defense markets.
DKube™, a standards-based, end-to-end machine learning platform, based on Kubeflow and MLFlow, will be used in this article to demonstrate the workflow and key capabilities for monitoring, retraining, and redeploying a model.
Model Monitor Fundamentals
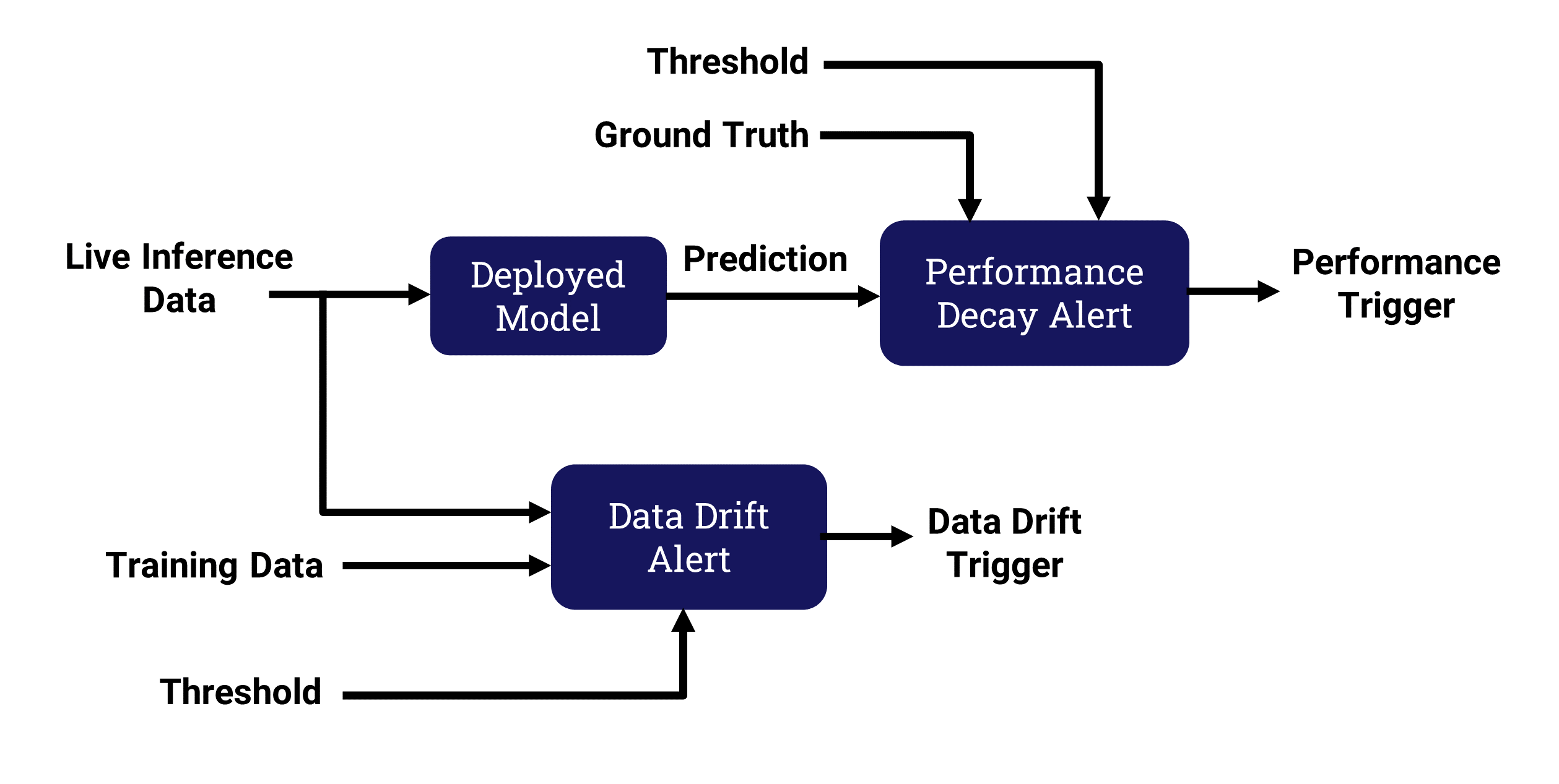
The basic idea behind model monitoring is to compare the current inference environment or outcomes to what was used during the training phase of the model.Differences between these 2 are calleddrift or decay.
The common types of deviation are data drift and performance decay.

Data Drift
The original training for a model uses datasets that are thought to represent the inputs for live inference. The model code and hyperparameters are tuned to that expectation. This generally provides an acceptable result - as long as the live inference data remains similar to the training data.
However, over time this expectation may no longer match reality. In many cases, the original training data will no longer reflect the current live data.
Input data that no longer matches the training data is called data drift. It is not necessary to calculate how well the model is performing to identify data drift. It is assumed that if the input data deviates significantly, the model is less likely to remain accurate.
Data drift is the simplest type of deviation to determine, since it doesn’t require any information about how well the current inference is performing. Improving the model simply involves using new data that better represents the current live data stream.
Performance Decay
A more sophisticated monitor measurement takes into account how the model is actually performing with the current live data. Even with data inputs that match the original training data, the model results may still be unacceptable for the following reasons:
- The relative importance of input features may change
- The accuracy of the results may need to be improved based on experience or competition
Models that do not provide the expected output results are experiencing performance decay. In order to determine how well a model is predicting outcomes based on the live input data, model metrics for the live inference are calculated. In order to determine the metrics, the correct prediction needs to be added to the input dataset, similar to a dataset used for training. The correct prediction is called ground truth..
Addressing the Problem
Determining that the inputs or predictions are no longer within tolerance is just the first step. In order to remedy the situation:
- The reason for the degradation must be determined
- The model must be retrained with better inputs
- The resulting model must be redeployed
The rest of this article explains how this is accomplished.
Executive Dashboard
The ability to measure a model’s effectiveness depends upon how easily the various stakeholders can review how the model is performing compared to the business goals.

The most effective way to address these requirements is to have a graphical view of the monitoring system, showing any problems in one place for the timeframe of interest.
An example of a dashboard is shown here. It provides a list of monitor runs on a graphical timeline, and a summary of how many alerts were created for that run. In addition, it provides a list of current monitors with their status. Later in this article, we will explain how that can be used to determine the reason for an alert.

Identifying the Root Cause
From the dashboard, the process of determining what is causing the drift or decay begins. This happens in a hierarchical manner.
- The first step is to choose one of the monitor runs from the graph in order to determine which monitor has triggered it
- Selecting that monitor will call up a screen with more details on that monitor
Depending upon whether the problem is input data drift or output performance decay, the steps are a little different. But conceptually, in each case the deviation is quantified, and the root cause is identified in order to determine what needs to be modified to better achieve the goals.

For example, in the image above, data drift is analyzed.
The graph provides a quick snapshot of where the monitor is having trouble, showing where the alerts are happening. The table below visually shows how the original training data compares to the current live prediction data, and how each feature impacts the outcome. Finally, the overall drift trend is shown to provide the context of how the drift is occurring over time.
Based on this information, an updated set of input datasets can be created to better match the current live inference data.
ReTraining a New Model
Once the user has identified the reasons for the drift or decay, the model needs to be retrained to address the problem. The complexity of the retraining depends upon the nature of the deviation.

In each case, the retraining approach will depend upon how seriously the outcomes are impacted.
- This can be as straightforward as running a hyperparameter optimization sweep on the new data
- It might be necessary to go back as far as Feature Engineering to improve the dataset extraction
- In some cases, coding enhancements will be required
For all of these possibilities, a key requirement is to easily go back to the original training run so that the improvements can be performed incrementally, starting with the current datasets, code, and hyperparameters.
For this to be possible, the full lineage of the model needs to be maintained as metadata throughout the life cycle of the model. The environment can then be cloned, and training can move forward using the normal workflow.
ReDeploying the Improved Model
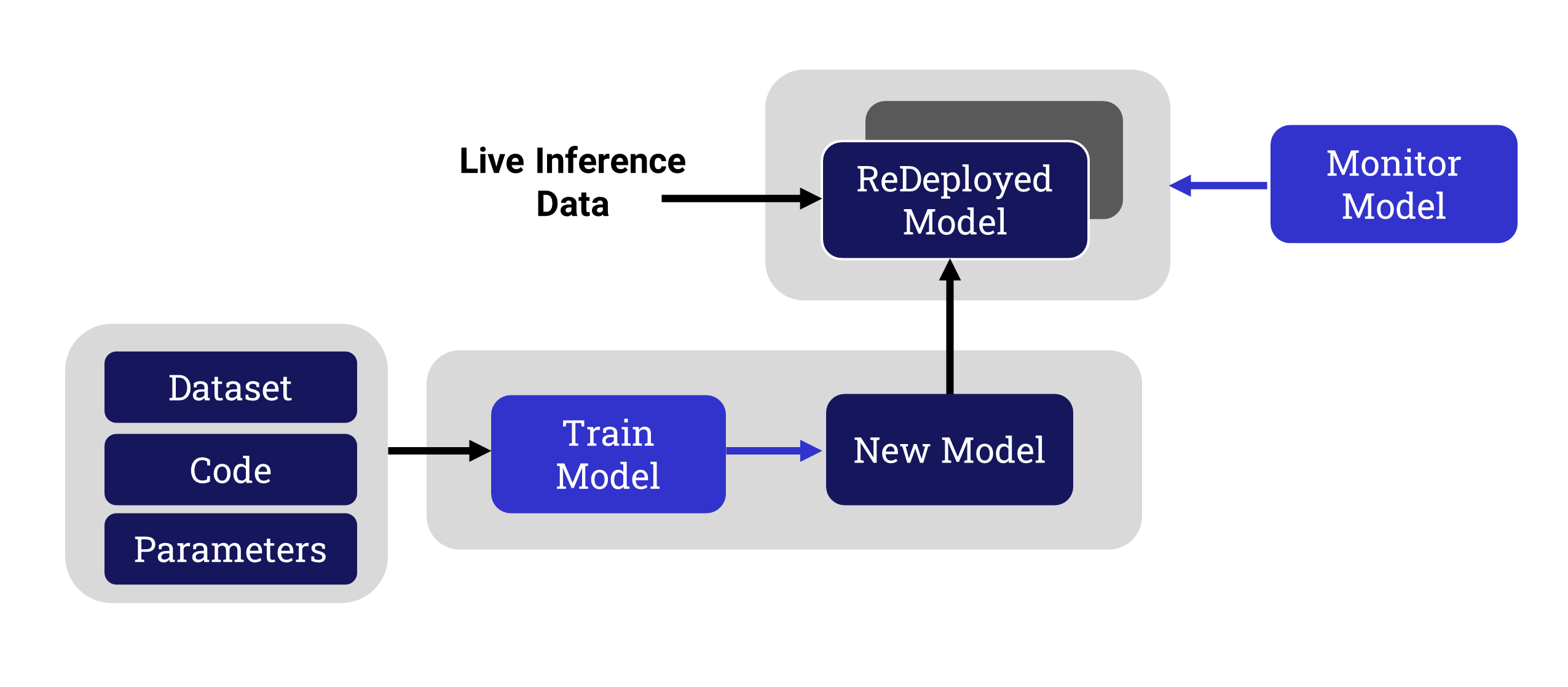
The retraining phase results in a new version of the model that better addresses the business goals of the organization. The new model needs to be deployed to the production server after the Production Engineer compares the revised model to the one that is no longer effective.
After deploying the updated model, it is important for the monitoring system to continue to review the results, since this new model will also have a shelf life.
The monitor configuration, including any alerts that have been set up, should automatically transfer to the new model, offering continuity with a minimum of effort.
One Package to Rule them All
This article has explained the purpose and workflow of a state-of-the-art model monitoring system.
- The model outcomes are continuously monitored to ensure that they achieve the business goals of the organization
- Significant deviations from those goals are remedied by a retraining operation, starting with the current set of inputs and environment
- The updated model version is deployed, and the whole process starts again
Ideally, this cycle is achieved within a comprehensive machine learning platform to allow coordination among the different groups, enable fast and easy enhancements, and to conform to regulatory and governance requirements.
DKube, a standards-based, end-to-end machine learning platform, based on Kubeflow and MLFlow, provides this capability, and was used for the examples shown here.
For more details on DKube and its monitoring capability, please go to www.dkube.io or email us at info@dkube.io.





