

How to launch hyperparameter tuning runs taking advantage of the Katib based hyperparameter tuning available in Kubeflow. Pick the best model from the multiple training runs as the winner based on pre-set criteria.
How to launch hyperparameter tuning runs taking advantage of the Katib based hyperparameter tuning available in Kubeflow. Pick the best model from the multiple training runs as the winner based on pre-set criteria.
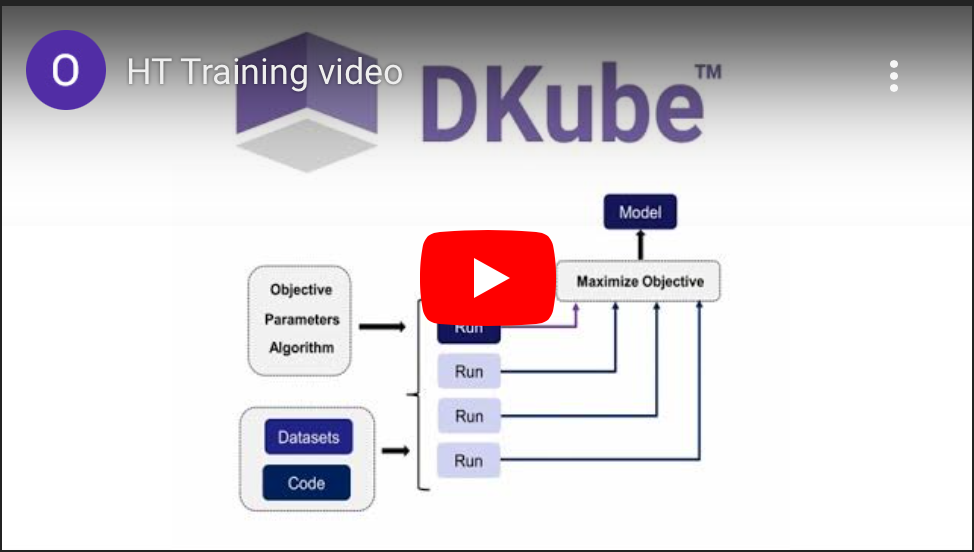
How to launch hyperparameter tuning runs taking advantage of the Katib based hyperparameter tuning available in Kubeflow. Pick the best model from the multiple training runs as the winner based on pre-set criteria.





